SAP Classification Explained Part 2: Classification Tables
2013-02-12 ABAP Classification Tables
After I introduced you to the classification system in SAP ERP® in the first part of this series, I’d like to go into more technical detail and explain the data model that is behind the classification. Why is this relevant? While it’s true that there are function modules to read and write classification data, sometimes (and by sometimes, I mean most of the times) it’s faster to re
Recommended Now
All-new Echo Dot Smart speaker with Alexa
This bundle includes Echo Dot (3rd Gen) Charcoal and Philips Hue White A19 Medium Lumen Smart Bulb, 1100 Lumens. Built in Smart Home hub. Ask Alexa to control Zigbee-compatible devices. No additional Philips Hue hub required. Two choices for easy smart lighting - Start setting the mood with Hue Smart bulbs and your Echo device, supporting up to 5 Hue Bluetooth & Zigbee smart bulbs. Add the Hue Hub for whole-home smart lighting (up to 50 light points) and bonus features.
Check it out on amazon.com →

This will be demonstrated in the next part of the series. First, however, I will introduce the tables that are involved. I also prepared a handy cheat sheet which you can use to get a quick overview about the relevant classification tables.
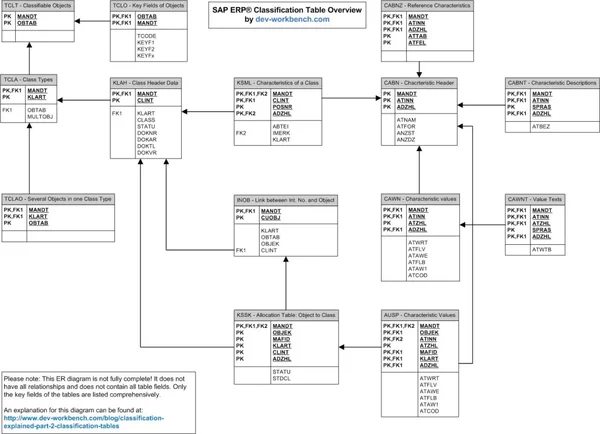
These are the relevant classification tables in SAP ERP.
Note that this cheat sheet does not include all table fields. The key fields are complete, but non-key fields are only listed if necessary for the following explanation.
Classifiable Objects – Table TCLT
TCLT is the starting point for classification. It defines the Classifiable Objects, meaning that only objects listed in this table can be classified. It contains the primary data table for the object (for example table EQUI) in the field OBTAB. This field plays an important role in the classification data model.
Object Keys – Table TCLO
Table TCLO defines how the Object Key that is used throughout classification in SAP ERP® is built. Usually, the object key corresponds to the key fields of the object table, but this does not have to be so. In customizing, it’s possible to use up to 9 fields from the object table to build the classification key of objects. The names of these fields are saved in the fields KEYF1 to KEYF9 in table TCLO. Let me give you an example (from plant maintenance, of course): Table IFLOT, which contains functional locations, is listed in TCLT as classifiable. In table TCLO, the field KEYF1 contains the entry TPLNR. Other fields are not filled. That means that the object key for functional locations throughout the classification system will be the field IFLOT-TPLNR (which, by concidence, is the primary key for the functional location table). For keys that consist of more than one field, the field values are concatenated. This means that for example plant-independent batches, which have the table MCH1 and the key fields MATNR and CHARG, will have the concatenated value of MCH1-MATNR and MCH1-CHARG as their classification key.
Class Types – Table TCLA
After defining the classifiable objects and their key, it’s time to check the Class Types. These are saved in table TCLA with all their important properties. Usually, class types correspond to exactly one object type – for example, the class type 002 can be used only for PM equipments. Consequently, the table EQUI is saved in the field TCLA-OBTAB. However, it’s also possible to classify more than one object type with a single class type – for example, class type 023 can be used for batches and materials. If this is the case, TCLA-MULTOBJ contains an ‘X’ – note this for later because we will be needing it when we talk about table INOB. Since more than one OBTAB is required in such cases, entries in another table are made.
Multiple Objects in Class Types – Table TCLAO
If more than one object table is required per class type, they will be stored in table TCLAO with a reference to table TCLA. The settings in TCLA will be overridden by those in TCLAO in such cases.
Class Headers – Table KLAH
Of course, after class types are defined, we can create classes for them, as demonstrated in part one of this series. The header data for classes is stored in table KLAH. This table introduces the Internal Class Number which is stored in the field CLINT. It is needed to find out which objects are classified in a certain class. The textual identifier that you enter during class creation (such as “CAR”) is stored in field CLASS.
Characteristics – Tables CABN and CABNT
Characteristic Headers are stored in table CABN. They also have an internal ID in field ATINN, which is needed to read classification data for this characteristic. The other key field, ADZHL, is only used if Engineering Change Management (ECM) is in use. It is then incremented for each change done. If ECM is not used, ADZHL has an initial value (0000). This applies to all tables which have ADZHL as key field. The textual characteristic identifier is stored in field ATNAM. To read the text for a characteristic, you’ll have to look into table CABNT additionally.
Reference Characteristics – Table CABNZ
If a characteristic is a Reference Characteristic, it has an entry in CABNZ. Here, the table and field to which it refers are saved.
Characteristic Values – Tables CAWN and CAWNT
The table CAWN contains the proposed or allowed values for a characteristic if the “Allowed Values” strategy is in use. If other strategies, such as check table, are used, CAWN does not contain any values. Again, to read the value text in the correct language, table CAWNT has to be read.
Allocation of Characteristics to Classes – Table KSML
After all these master data tables, now we’re starting to come to the root of classification. As we learned, characteristics must be assigned to classes in order to work. This assignment is saved in table KSML. For each internal class ID (CLINT), it has the position of the characteristic in the class in field POSNR, which is just incremented by one with each characteristic added. The actual characteristic ID is in the non-key-field IMERK. Again, the field ADZHL is not relevant if you’re not using ECM. A quick example is in order here. Let’s remember the example from the first part – we assigned the characteristic COLOR to the class CAR. This is what it looks like in KSML:
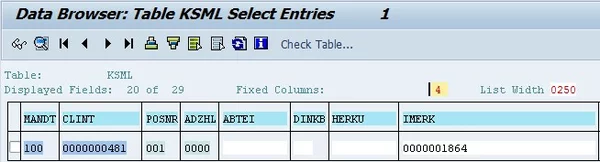
The entry in KSML
The class CAR has the internal class number 0000000481 in CLINT. Since it’s in first position, POSNR is 001. The internal ID of the characteristic COLOR is saved in field IMERK.
Mapping of Internal Numbers to Objects – Table INOB
Remember how I said the field TCLA-MULTOBJ would become important? Here it is now. To explain what the table INOB does, we have to remember again that it’s possible to classify multiple objects with one class type. This is the case for class type 023 (batches) – you can classify materials and batches with it. However, this leads to a problem. Material numbers have a defined classification object key, batches have a different one. How does the classification system know with which key it should read classification data? This is where INOB comes into play. For class types where TCLA-MULTOBJ is set, the classification object key as defined in TCLO is mapped to an internal number, which is then used as the object key in the tables that contain classification data (KSSK and AUSP). That means that for class types that allow the classification of multiple different objects, you need to map the external object key that is defined in TCLO to the internal one defined in INOB. Only with this internal key is it possible to read data from KSSK and AUSP. If the class type you’re using does not allow classification of multiple objects, the external object key can be used to read data directly from the data tables. In this case, table INOB is completely irrelevant and will hold no entries for the class type. Some additional information: Normally, after classification of multiple objects has been activated, it cannot be revoked again if objects have been classified. Consequently, it can’t be activated afterwards as well. There are, however, two reports mentioned by SAP to reorganise this data: RCCLUKA2 and RMCLINOB. For more information on this, read the F1 help in SPRO -> Cross-Application Components -> Classification System -> Classes -> Maintain Object Types and Class Types -> Details of your Class Type -> Field Multple objs allowed. In a nutshell:
- If TCLA-MULTOBJ is set for your class type, read the internal object key in field INOB-CUOBJ to access classification data. Use the external classification key (which is determined by the settings in table TCLO) as selection criterion on field INOB-OBJEK.
- If TCLA-MULTOBJ is initial for your class type, use the external object key to access classification data directly.
Allocation of Objects to Classes – Table KSSK
After this prelude, it’s time to get down to the real classification data. If an object is classified in a class, this is saved in table KSSK. KSSK is one of the most important tables in the SAP ERP® classification system. If you want to know if an object is assigned to a certain class, that’s where you look it up. The key fields are set up as follows:
- OBJEK is the classification key of the object you’re looking for. It’s either the external one as defined in TCLO or the internal one from INOB.
- MAFID is called Indicator: Object/Class. This field contains an “O” if we’re classifying anything but a class, in which case it contains a “K”.
- KLART is the class type we’re reading from.
- CLINT is the internal ID of the class which comes from table KLAH.
- ADZHL, once again, is used only when Engineering Change Management is active.
Characteristic Values – Table AUSP
Once you know this data, you can go ahead and read the actual classification values from AUSP. You’ve seen all the key fields in here before, so I’m not going to comment these again. Basically, you need your object key (internal or external), your internal characteristic ID and the class type. However, notice that there are several different fields for values, depending on which data type the characteristic in question has. Reading these values is a bit tricky and deserves its own article.
Summary
Congratulations if you stayed with me throughout the whole article – you now know exactly how the SAP ERP® classification system’s data model works. However, that’s not the end of the story. If you’ve taken a look in table AUSP, you might have noticed that the values saved in there are not exactly formatted as one would expect. This is why the next part of this series is dedicated to reading and displaying data from AUSP. Stay tuned!